

Gemini 2.0: The Cheapest Model for AI Apps

Announcement: My introduction to AI agents has been released. I’m also working on a prompting guide. Let me know if there are any other posts you’d like to see from me. In the meantime, here’s some news
An hour ago, Google announced their latest model, Gemini 2.0
The News
Performance
It performs at least as good as ChatGPT-o1 at a substantially lower cost. Google tends to have the best cost-to-performance ratio which is why I suggest using Gemini if you are building AI apps:


Multimodality
It’s multimodal which means it can do image and audio output. And it can take crazy inputs like .zip files!
Coding
Has good reviews thus far, and includes the standard set of tools:
structured outputs (like if you want a particular format or file type),
function calling (if you want a particular input or keyword to trigger a function)
web search
code execution
Larger Context Windows
Can handle a context window (“memory”) of 2m tokens! 1 word is 2-3 tokens, which means 2m tokens is ~800,000 words. Contrast this with ChatGPT and DeepSeek which can only handle a context window of 128,000 tokens, about 50,000 words. This doesn’t mean more accurate outputs, but it does mean that you can input more data in your prompt:
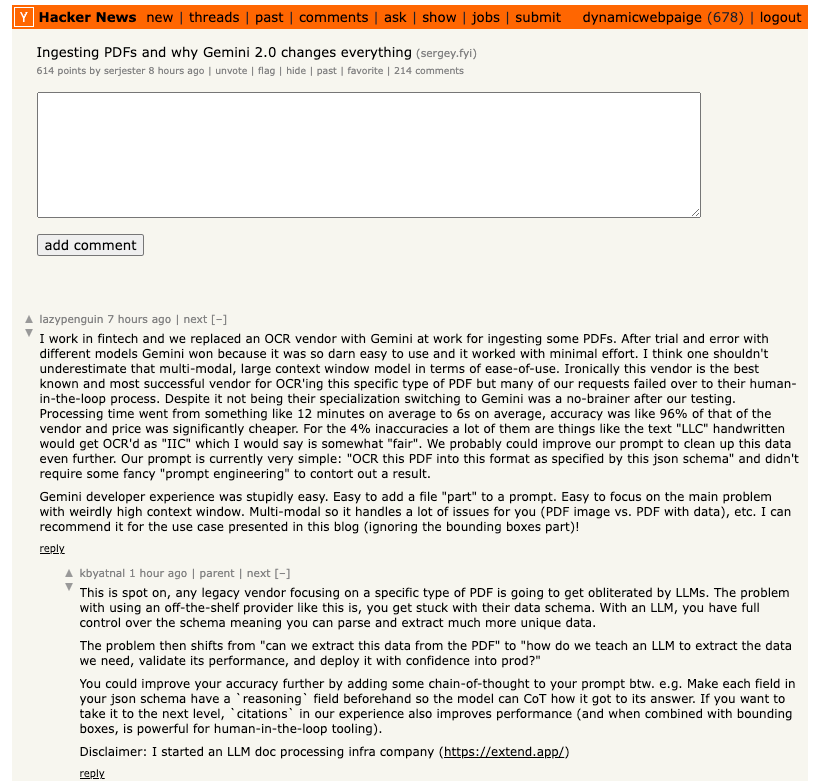
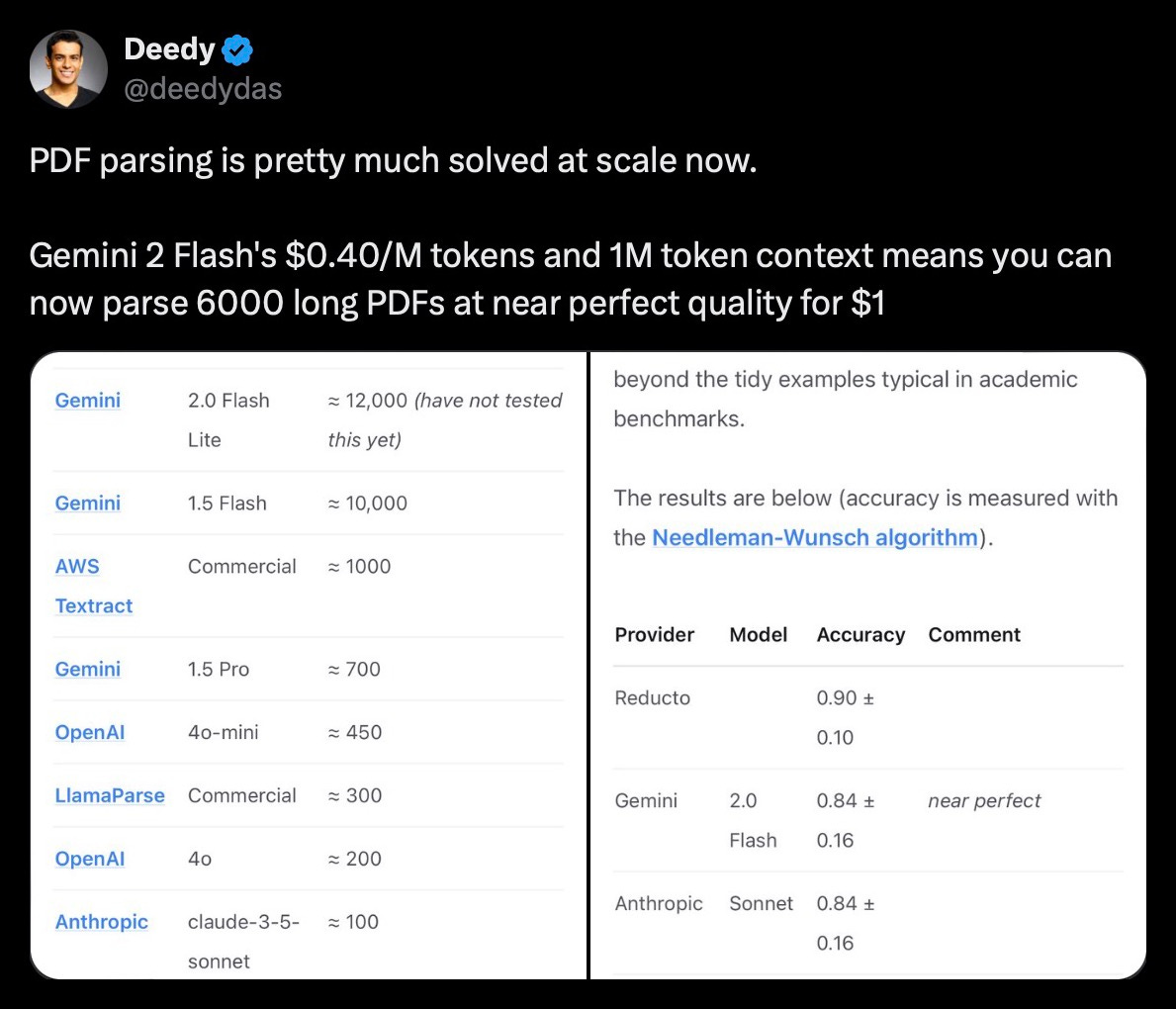
Detailed Chain-of-Thought




My Thoughts
I would not ignore Google. Google has access to an enormous amount of private data. People use it for everything from email, search, YouTube, docs, sheets, slides. They will integrate their models across so many products:

We all know Google’s first attempt at AI was a joke at first. The performance was nowhere near ChatGPT. But now that DeepSeek released all their research, the information is already out there–it’s only a matter of time until Google’s models improve
Even if Google has a problem with developing a competitive model, it won’t matter because they can reach a wider audience
Between September 2024 and December 2024, the market share of Google Gemini amongst developers increased from 5% to 50%

Additionally, where other companies will have problems with data, Google won’t. “Data is the new oil” as they say
I believe future model improvement is going to require increasing amounts of data. We know this because most of the recent ChatGPT updates have been based on reinforcement learning, which requires more data than other training strategies, such as supervised or unsupervised learning
And who’s better than Google at data collection? They have access to the biggest video library, everyone’s emails, everyone’s drive files, and they’ve perfected searching and indexing the entire web. I think this is going to be the moat that keeps them ahead
Edit: An excellent addition by
:
Great insights. I agree with you and think if Google play their cards right, they have what it takes to lead the AI race. Now that it seems like Deepmind are spearheading efforts, things are very promising. Apart from the many data pools they have in the form of email, search, YouTube, docs, sheets and slides; they're also pushing the fort with NoteBookLM, Google AI Studio and Google Deep Research.
Also, don't forget synthetic data. It seems that will have a large role to play in all of this. Nvidia Omniverse and Cosmos have shown how valuable this is.
Lastly, don't bet against open source. They might just be the dark horse in all of this.
Google's Project Astra seems like a big bet on smart glasses to me. Interesting play. Mariner makes sense to me - similar to OpenAI Operator and a very natural productivity oriented agent.
But to my knowledge, Astra is unique - do you know of other big players who are pushing this with-you-all-the-time multi-modal copilot?